PostgreSQL: 详解索引 Include 子句

有些数据库 —— 比如 Microsoft SQL Server、IBM Db2 及发行版 11 之后的 PostgreSQL —— 在创建索引语句时都支持 include 子句。PostgreSQL 引入这个特性是促使我发这篇长文解释 include 条件的直接原因。
深入细节之前,我们先回顾一些(非聚簇) B-树的索引是如何工作的以及全能的 index-only scan 是什么。
内容概要:
- 回顾:B-treee 索引
- 回顾:Index-Only Scan
- Include 子句
- Include 列的过滤
- Include 子句的唯一索引
- 兼容性
- PostgreSQL: 可见性检查前不会过滤
回顾:B-treee 索引
要理解include子句,你必须先明白使用索引影响3层数据结构:
- B-tree
- B-tree 叶节点级别上的双向链表
- 表格
前两个数据结构组成了索引,因此它们可以组合成单独的一项,比如,"B树索引"。我倾向于将它们分开,因为它们服务于不同的需求并且在性能上有不同表现。再者,解释 include 子句需要对其进行区分。
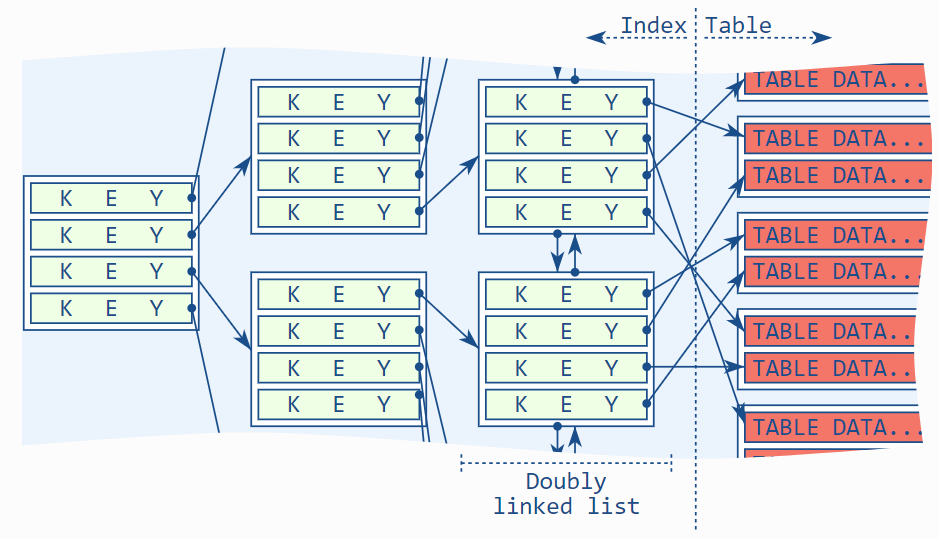
一般情况下,数据库软件遍历 B 树叶子节点的第一级查找第一个匹配的实体。然后沿着双向链表直到找到所有匹配的实体(2)并最终在表(3)中获取所有这些匹配的实体。实际上,最后两步是可以交替进行的,不过对理解整体概念无关。

下面的公式让你对每一步需要多少读操作有一个初步的印象。这三个组件的和是索引访问的总工作量。[假定每个页/块的索引是 100]
- B-tree: log100(<表的行数>), 通常小于 5
- 双向链表: <从索引中读取的行数> / 100
- 表: <表中读取的行数>[最差的情况:所有需要的行在不同块中]
如果只加载少数行数,B 树在总体工作量中的贡献最大。当你只是从表中获取少数几行时,这一步起首要作用。其他情况下——少数几行或很多行——双向链表都是次要因素,因为它将类似的值存储在相邻位置,以便单个读操作可以获取 100 条甚至更多行数。该公式通过各自的除数反映这一点。[尽管双向链表可能变成限制因素,比如,index-only 扫描或更可能地,当从表中提取的行数远小于从双链表中读取的行数时]
注意
如果你在想“这就是为什么我们有聚簇索引”,请读本篇文章:“Unreasonable Defaults: Primary Key as Clustering Key”.
优化的一般思路是,做更少的工作实现同样的目标。对于索引访问,这意味着如果其中没有任何需要的数据,数据库软件会忽视访问数据结构。
回顾:Index-Only 扫描
Index-only 扫描实际这么做的:如果需要的数据在索引的双向链表上中可以获取得到,它就会忽略对表的访问。
参考下面关于索引和查询的例子:
CREATE INDEX idx
ON sales
( subsidiary_id, eur_value )SELECT SUM(eur_value)
FROM sales
WHERE subsidiary_id = ?乍一看,你可能会想,为什么 eur_value 会在索引定义出现中——它在 where 条件中并没有提及。
B-tree 索引对许多子句都有帮助
这是常见的误解,以为索引只对 where 子句有用。
B-tree 索引也对 order by, group by, select 和其他子句有用。只是索引的 B-tree 部分—而非双向链表—不能被其他子句使用。
本例的关键点是,B-tree 索引刚好有所有需要的列——数据库软件不需要访问表格本身。这就是我们将其称为 index-only 扫描。
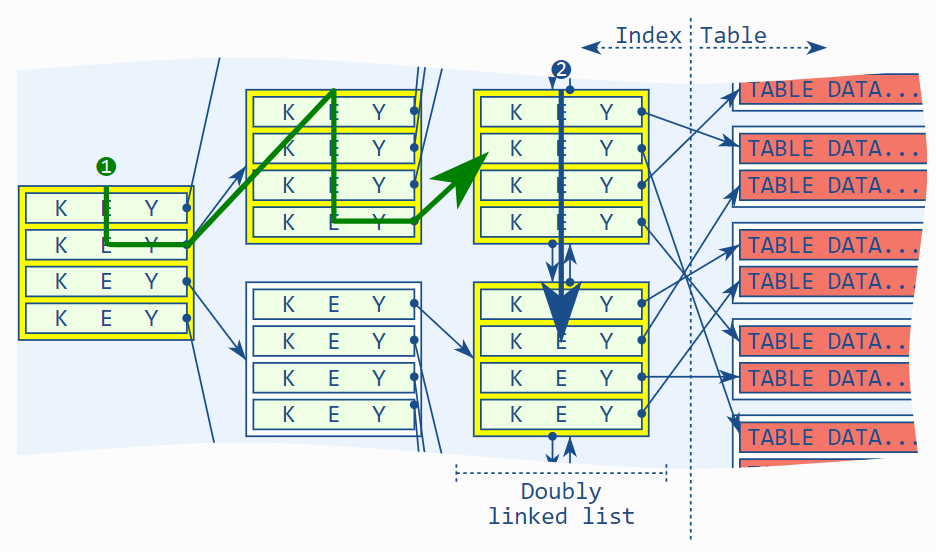
使用上面的公式,如果只有少数行满足 where 子句,那性能优势非常小。另一方面,如果 where 子句接受很多行,比如百万行,读操作的次数基本上可以减少百倍。
注意
index-only 扫描提升性能一两个数量级并不少见。I
上例实际上使用了双向链表——B-tree 的叶节点——包含了 eur_value 列这样的情况。虽然其他的 B-tree 节点也存储该列,该查询没有使用这些节点的信息。
Include 子句
Include 子句允许我们将整个索引都需要的列(关键列)和只需要在页节点需要的列(include 列)区分开来。这意味着,它允许我们从非页节点中将列删除,如果我们不需要的话。
覆盖索引(Covering Index)
术语“覆盖索引” 有时候我们会在 index-only 扫描或 include 子句的上下文中使用。因为这个术语常常有不同含义,我一般避免使用。
重要的是,给定的索引是否可以通过 index-only 扫描方式支持给定查询。该索引是否有 include 子句或包含所有无关的表格列。
使用 incude 子句,我们可以定义优化这个查询的索引:
CREATE INDEX idx
ON sales ( subsidiary_id )
INCLUDE ( eur_value )该查询依然可以使用这个索引进行 index-only 扫描,因此性能上基本上是一样的。
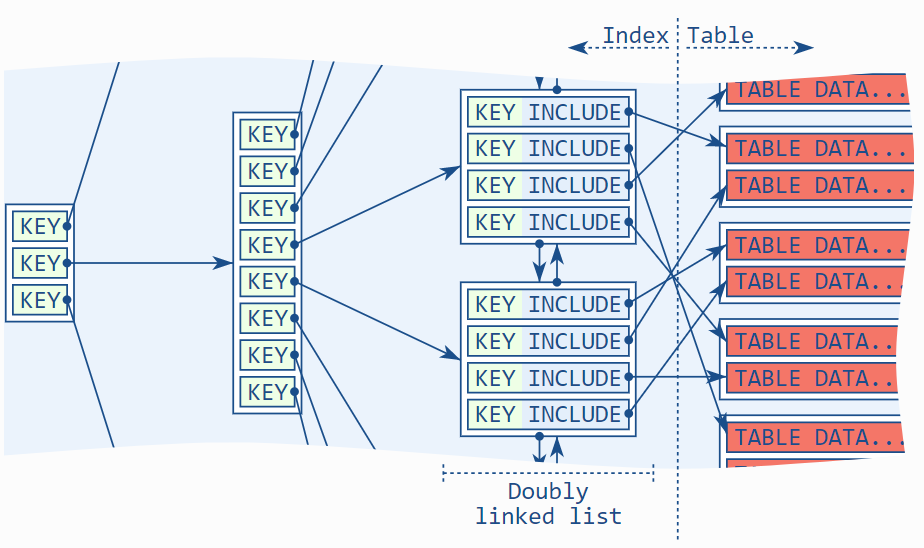
除了上面表格明显的差别,还有一个更为微妙的不同:叶节点实体的排序不考虑 include 列。索引仅通过关键列进行排序。[] 这有两个后果:include 列不能用于阻止排序,也不能用于唯一性(见下文)。
长度限制
index元素的最大长度是有限制的。这意味着,你不能总是把所有想要索引的列都加入索引。
有些产品—特别是 SQL Server—在索引的 key 部分做了更严格的限制,就如它们对 include 列的总索引长度的所做的那样[SQL Server: 最大的 key 长度是 900/1700 bytes, 最大总索引实体长度是 8060 bytes]。在这样的系统中,如果你不能把所有需要的列都放入索引key中,你可以将它们放入到 include 子句。即使这些列不能用于访问预测,它们仍允许在这些列上检查条件而不必访问表格。
相较于最初的的索引定义,使用 include 子句的有一些优势:
- 索引树的层级可能更少 (<~40%)
因为双向链表以上的树节点不包含 include 列,数据库在每个块中可以存储更多分支,因此索引树的层级可能更少。
- 索引会略小 (<~3%)
由于树的非页几点不包含 include 列,索引的总大小会稍微略小。不过索引的页节点需要最多的空间,因此在其余节点中潜在的节省的空间就非常小了。
- include 索引的目的
这绝对是 include 子句最被低估的优势:列为什么会出现在索引中,索引本身的定义给予了说明。
这里我要对最后一项加以解释。
如果要扩展现有的索引,明确知道这些索引为什么这么定义很重要。自由修改索引而不至于破坏任何其他查询,是这一认知的直接结果。
下面的查询证实了这一点:
SELECT *
FROM sales
WHERE subsidiary_id = ?
ORDER BY ts DESC
FETCH FIRST 1 ROW ONLY如前,对于给定的子公司(subsidiary),该查询获取最近的 sales 实体(ts 为 timestamp)。
要优化该查询,最好有一个以关键列(subsidiary_id,ts)开始的索引。有了这个索引,数据库软件可以直接导航到该subsidiary 的最新条目,并立即返回。不需要读取和排序该 subsidiary 的所有条目,因为双链表是根据索引键排序的,即任何给定子公司 subsidiary 的最后一个条目必须具有该子公司最大的 ts 值。使用这种方法,查询的速度基本上与主键查找一样快。
在为该查询添加新的索引前,我们需要先检查是否现有的索引可以用来修改(扩展)以支持这个技巧。这是通用的好的实际,因为扩展现有的索引比添加新的索引对维护的开销通常影响较小。不过如果修改现有索引,我们需要确保不会让该索引对其他查询的用处变小。
如果我们对比初始索引定义,我们碰到一个问题:
CREATE INDEX idx
ON sales
( subsidiary_id, eur_value )要使该索引支持上述查询的 order by 子句,我们需要在目前两个列之间插入 ts 列:
CREATE INDEX idx
ON sales
( subsidiary_id, ts, eur_value )不过,这可能会使得位于第二位的 eur_value 列的索引作用变小,比如,当其出现在 where 或 order by 子句中时。修改这个索引涉及一个相当大的风险:破坏其他查询,除非我们知道没有这类查询。如果不知道,通常来说最好还是保持该索引原来的样子并为新查询重新创建一个。
如果我们使用 include 子句来看待这件事,就完全不一样了。
CREATE INDEX idx
ON sales ( subsidiary_id )
INCLUDE ( eur_value )由于 eur_value 在include子句中,因此它不在非页节点中,也就不再用作树的查找或排序。将新列添加到key部分的后面是相对安全的。
CREATE INDEX idx
ON sales ( subsidiary_id, ts )
INCLUDE ( eur_value )即使对其他查询而言,在导航影响上有一些小的风险,通常还是值得冒险的。[]
从索引发展的角度看,如果这是你需要的,将列放入 include 子句是非常有帮助的。刚刚添加的索引列将成为 index-only 扫描的主要候选。
Include 列过滤
目前为止,我们关注了 include 子句如何启用 index-only 扫描。让我们看另外一个案例,在索引中增加一个额外列来获益。
SELECT *
FROM sales
WHERE subsidiary_id = ?
AND notes LIKE '%search term%'我已经将搜索项设为字面量,以展示前导和尾部通配符的—当然你可以在你的代码中使用绑定参数。
现在,我们来考虑一下这个查询右边的索引。很明显 subsidiary_id 需要被放在第一位。如果我们采用上面的索引,它已经满足了这个需求:
CREATE INDEX idx
ON sales ( subsidiary_id, ts )
INCLUDE ( eur_value )就像刚开始所说的那样,数据库按照三个步骤使用该索引:(1)使用 B-tree 查找给定 susidiary 的第一个索引实体;(2)沿着双向链表查找该 subsidiary 的所有 sales;(3)从表格中获取所有相关的 sales,移除那些在 notes 列上不匹配的项并返回剩下的行。
问题在该过程的最后一步:访问表并加载行,但是不知道它们是否能满足最终的结果。通常情况下,表访问在运行查询中是最大的开销者。加载那些甚至最终没有选中的数据是巨大的性能消耗。
重要
要避免加载那些不影响查询结果的数据。
这一查询的调整之处在于,它用了中间的 ”like" 查询。普通的 B-tree 索引不支持搜索这类查询。不过 B-tree 索引依然支持在这种模板上进行过滤。注意重点是,搜索vs.过滤。
换言之,如果 notes 类出现在双向链表中,数据库会在从表格中读取该行之前应该这个 like 模板(非 PostgreSQL, 见下文)。如果like模板不匹配这就阻止了表访问。如果表中有更多的列,仍然会访问表获取满足 where 子句的这些列—因为 select *。.
CREATE INDEX idx
ON sales ( subsidiary_id, ts )
INCLUDE ( eur_value, notes )如果表中有更多列,索引不会启用 index-only 扫描。尽管如此,如果与 like 模式匹配的行部分非常少,它可以使性能接近于 index-only 扫描。在相反的情况下,如果所有行都与模式匹配,则由于索引大小的增加,性能会稍差一些。然而,平衡点很容易达到:为了提高整体性能,通常情况下,like 过滤器只需删除一小部分行就足够了。性能将因所涉及列的大小而异。
Include 子句唯一索引
最后不得不提的是,include 子句完全不同的一面:使用 include 子句的唯一索引只考虑关键列的唯一性。
这就允许我们创建在叶节点中拥有额外列的唯一索引,比如,用于 index-scan 扫描
CREATE UNIQUE INDEX …
ON … ( id )
INCLUDE ( payload )该索引避免 id 字段重复,同时支持下面查询的 index-only 扫描。
SELECT payload
FROM …
WHERE id = ?注意,这个 include 子句并不会严格要求这个行为:数据库只需一个索引,该索引用唯一的关键列作为最左边的列(有其他额外的列也好,不影响),就能对唯一约束和唯一索引做正确的区分,
对于 Oracle 数据库,正确的语法是:
CREATE INDEX …
ON … ( id, payload )ALTER TABLE … ADD UNIQUE ( id )
USING INDEX …兼容性
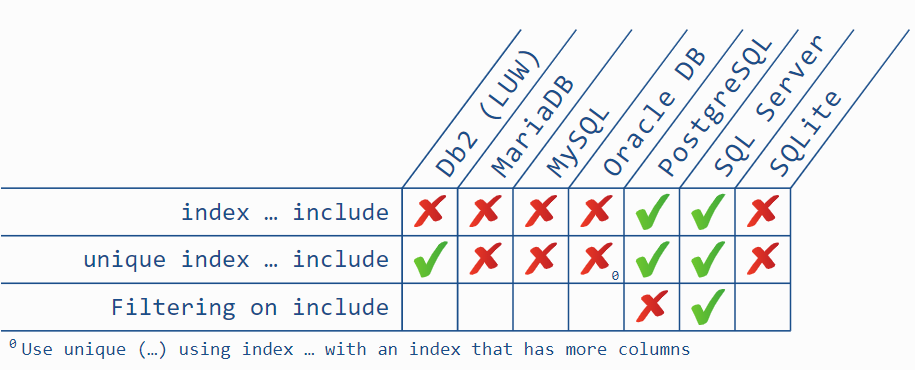
PostgreSQL: 可见性检查前不会过滤
PostgreSQL 数据库在索引层级上使用过滤器时,有一个限制。简单地说,除了少数情况外,它不进行过滤。更糟的是,这其中的一部分只有当数据存储在索引关键部分才生效,而存在 include 子句中时才不生效。这意味着将字段移到 include 子句可能对性能产生负面影响,即使上述逻辑仍然适用。
详细版就要从这么一个事实开始:PostgreSQL 在表格中保留了旧版本的行记录,直到它们对所有事务可见,vacuum 进程才在稍后的某个时间点将它们删除。要想直到一个行版本是否(对某个给定事务)可见,每个表有两个属性说明行版本何时创建及删除: xmin 和 xmax。只有当前事务在 xmin/xamx 范围内,该行才可见。
不幸的是,xmin/xmax 的值不在 index 中存储。
这意味着,每当 PostgreSQL 查看条目时,它都没办法直到该条目是否对当前事务可见。它可能是一条已删除的条目或者是一条还没被提交的条目。规范的做法是,去表中查询检查 xmin/xmax 的值。
后果是 PostgreSQL 中就没有 index-only 扫描这一回事,无论你在索引中放入多少列,PostgreSQL 总要检查其可见性,而这在索引中查找不到。
当然,PostgreSQL 中还是有 Index Only Scan 操作 — 不过仍然需要在索引之外访问数据检测每一行版本的可见性。Index Only 扫描首先会先去检查 visibility map。这个 visibility map 非常紧凑,因此,比起从表中获取 xmin/xmax,这里读操作的次数一般会更少。不过,visibility map 也不总是可以给出一个明确的答案:visibility map 只能说明该行是否已经可见,还是可见性还未知。后者的情况,Index Only 扫描仍然需要从表中获取 xmin/xmax。(在 explain anylaze 分析中显示为 “Heap Fetches” ).
岔开话题聊可见性之后,我们回到主题,关于索引的过滤问题。
SQL 允许在 where 子句中使用任意复杂的表达式。这些表达式还可能导致运行时错误,例如 “division by zero”。如果 PostgreSQL 在确认相应条目的可见性之前评估这样的表达式,那么即使是不可见的行也可能导致这样的错误。为了防止这种情况,PostgreSQL 通常会在评估此类表达式之前检查可见性。
这个通过规则有一个例外。由于在搜索索引时无法检查可见性,因此可以用于搜索的运算符必须始终安全使用。这些是在各自的运算符类中定义的运算符。如果一个简单的比较过滤器使用来自这样一个运算符类的操作,PostgreSQL 可以在检查可见性之前应用该过滤器,因为它知道这些运算符可以安全使用。关键是只有关键列才有与它们相关联的运算符类。include 子句中的列没有-在确认其可见性之前,不会应用基于这些列的筛选器。这是我从 PostgreSQL 黑客邮件列表上的一个帖子中了解到的。
为了进行演示,以前面的索引和查询为例:
CREATE INDEX idx
ON sales ( subsidiary_id, ts )
INCLUDE ( eur_value, notes )SELECT *
FROM sales
WHERE subsidiary_id = ?
AND notes LIKE '%search term%'这个执行计划(为简洁做了修改),大致如下:
QUERY PLAN
----------------------------------------------
Index Scan using idx on sales (actual rows=16)
Index Cond: (subsidiary_id = 1)
Filter: (notes ~~ '%search term%')
Rows Removed by Filter: 240
Buffers: shared hit=54这个 like 过滤用在 Filter 中显式,而不是在 Index Cond 中。这意味着,它应用在整个表级别中。同时 shared hits 的数量对于获取 16 行数据来说,相当的高。
在 Bitmap Index/Heap Scan 中,这个现象更为明显。
QUERY PLAN
-----------------------------------------------
Bitmap Heap Scan on sales (actual rows=16)
Recheck Cond: (idsubsidiary_id= 1)
Filter: (notes ~~ '%search term%')
Rows Removed by Filter: 240
Heap Blocks: exact=52
Buffers: shared hit=54
-> Bitmap Index Scan on idx (actual rows=256)
Index Cond: (subsidiary_id = 1)
Buffers: shared hit=2这个Bitmap Index Scan 根本没有提到这like过滤器。相反它返回了 256 行—远多于满足 where 语句的 16 行。
请注意,这样的情况并非特别出现在 include 列。将 include 列移到索引关键列得到的也是一样的结果。
CREATE INDEX idx
ON sales ( subsidiary_id, ts, eur_value, notes) QUERY PLAN
-----------------------------------------------
Bitmap Heap Scan on sales (actual rows=16)
Recheck Cond: (subsidiary_id = 1)
Filter: (notes ~~ '%search term%')
Rows Removed by Filter: 240
Heap Blocks: exact=52
Buffers: shared hit=54
-> Bitmap Index Scan on idx (actual rows=256)
Index Cond: (subsidiary_id = 1)
Buffers: shared hit=2这是因为 like 操作符不是 operator 类的一部分,因此它被当作不安全的。
如果你适用 operator 类的操作符,比如,等号,执行计划就会改变。
SELECT *
FROM sales
WHERE subsidiary_id = ?
AND notes = 'search term'Bitmap Index Scan 现在采用了 where 语句中的所有条件,并且只将剩下的 16 行传给 Bitmap Heap Scan。
QUERY PLAN
----------------------------------------------
Bitmap Heap Scan on sales (actual rows=16)
Recheck Cond: (subsidiary_id = 1
AND notes = 'search term')
Heap Blocks: exact=16
Buffers: shared hit=18
-> Bitmap Index Scan on idx (actual rows=16)
Index Cond: (subsidiary_id = 1
AND notes = 'search term')
Buffers: shared hit=2请注意,这需要相应的列成为关键列。如果将 notes 列移回 include 子句,那它就没有关联的运算符类,因此 equals 运算符不再被认为是安全的。因此,PostgreSQL 推迟将此筛选器应用于表访问,直到检查可见性之后。
QUERY PLAN
-----------------------------------------------
Bitmap Heap Scan on sales (actual rows=16)
Recheck Cond: (id = 1)
Filter: (notes = 'search term')
Rows Removed by Filter: 240
Heap Blocks: exact=52
Buffers: shared hit=54
-> Bitmap Index Scan on idx (actual rows=256)
Index Cond: (id = 1)
Buffers: shared hit=2 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博