SQL性能解析:Where 语句

前文描述了索引的结构,并解释了索引性能不佳的起因。下一步,我们来学习如何在 SQL 语句中发现和避免这些问题。我们从 where 语句开始吧。
where 子句定义了 SQL 语句的查询条件,因此属于索引的核心功能领域:快速查找数据。虽然 where 子句在性能上有巨大的影响,语法经常上不太小心而导致数据库不得不扫描索引的很大部分。其结果是:写得不好的where子句是慢速查询的第一个组成部分。
本文解释了不同的运算符如何影响索引的使用,以及如何确保索引用于尽可能多的查询。最后一部分显示了常见的反模式,并提供了可提供更好性能的替代方案。
= 等号运算符
等号运算符既是最琐碎的SQL运算符,也是最常用的SQL运算符。影响性能的索引错误仍然非常常见,并且组合多个条件的子句特别脆弱。
文章将展示如何验证索引的使用,并解释连接索引如何优化组合条件。为了助于理解,我们将分析一个慢查询,以了解前一章中解释的原因对真实场景的影响。
主键
我们从最简单、最常见的where子句开始:主键查询。以本章中我们用到的 employees 表为例,定义如下:
CREATE TABLE employees (
employee_id NUMBER NOT NULL,
first_name VARCHAR2(1000) NOT NULL,
last_name VARCHAR2(1000) NOT NULL,
date_of_birth DATE NOT NULL,
phone_number VARCHAR2(1000) NOT NULL,
CONSTRAINT employees_pk PRIMARY KEY (employee_id)
)数据库自动未主键创建了索引。这意味着 employee_id 这一个字段上有一个索引,即使没有创建索引语句。
Tip
附录 C, “Example Schema” 包含用示例数据填充EMPLOYEES表的脚本。您可以使用它在自己的环境中测试示例。
要跟上文本,只要知道表中包含1000行就足够了。
下面的查询使用主键检索employee的名字:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123这个 where 子句不会匹配多行,因为主键约束保证 employee_id 值的唯一性。数据库不需要进入索引叶子节点 —— 遍历索引树就够了。我们可以使用所谓的执行计划进行验证:
Oracle:
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 2 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 2 |
|*2 | INDEX UNIQUE SCAN | EMPLOYEES_PK | 1 | 1 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=123)MySQL
+----+-----------+-------+---------+---------+------+-------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+-------+---------+---------+------+-------+
| 1 | employees | const | PRIMARY | 5 | 1 | |
+----+-----------+-------+---------+---------+------+-------+
Type const is MySQL’s equivalent of Oracle’s INDEX UNIQUE SCAN.Oracle 的执行计划展示了一个索引唯一性扫描(INDEX UNIQUE SCAN) —— 该操作只遍历索引树。它充分利用了索引的对数可伸缩性,可以非常快速地找到条目,几乎与表大小无关。
Tip
执行计划(有时也叫解释计划或者查询计划)展示了数据库用来执行一条SQL语句的步骤。附录A解释了用其他数据库如何检索及阅读执行计划。
访问索引后,访问索引后,数据库必须再执行一步: Table ACCESS BY INDEX ROWID操作,以从表存储中获取查询的数据(FIRST_NAME、LAST_NAME)。正如“慢速引,第一部分”中所解释的那样,此操作可能会成为性能瓶颈,但INDEX UNIQUE SCAN不存在这样的风险。此操作不能传递多个条目,因此不能触发多个表访问。这意味着慢速查询的成分不存在于INDEX UNIQUE SCAN中。
不带唯一索引的主键
主键不是必须唯一索引 —— 你也可以用非唯一索引。这种情况下,Oracle 数据库不适用索引唯一性扫描而是索引范围扫描操作。尽管如此,约束仍会保持键的唯一性,使得索引查询最多得到一个条目。
对主键使用非唯一索引的原因之一是可延迟约束。与在语句执行过程中验证的常规约束不同,数据库会推迟可延迟约束的验证,直到事务被提交。将数据插入到具有循环依赖关系的表中需要延迟约束。
联合索引
虽然数据库自动为主键创建索引,如果该键是有多个字段组成,还是有手动优化空间。在这种情况下,数据库会在所有主键列上创建一个索引,即所谓的联合索引(也称为多列、复合或组合索引)。请注意,联合索引的列顺序对其可用性有很大影响,因此必须谨慎选择。
为了演示,我们假定有一个公司合并。其他公司的employee加入到我们的employee表中,因此它变大了十倍。只有一个问题是:跨两家公司后 employee_id 不再是唯一的了。我们需要通过额外的标识(如 subsidiary ID)来扩展主键。这样新的主键有两个字段:employee_id 和 subsidiary_id,来重建唯一性。
新主键因此定义如下:
CREATE UNIQUE INDEX employees_pk
ON employees (employee_id, subsidiary_id)查询某个特定员工不得不考虑整个主键 —— 也就是说,subsidiary_id 也被使用了:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary_id = 30每当查询使用完整的主键时,无论索引有多少列,数据库都可以使用INDEX UNIQUE SCAN。但是,当只使用其中一个关键列时,例如,当搜索子公司的所有员工时,会发生什么?
SELECT first_name, last_name
FROM employees
WHERE subsidiary_id = 20执行计划说明了数据库没有使用索引。相反,它执行了 TABLE ACCESS FULL。因为数据库读取整个表格并根据where子句评估每一列。执行时间随着表的大小而增长:如果表增长十倍,TABLE ACCESS FULL 则花费十倍时间。这一操作的危险之处在于,它在小型的开发环境中足够快,而在生产环境中则会导致严重的性能问题。
全表扫描
TABLE ACCESS FULL, 也称作全表扫描,在某些情况下,是最有效的操作,特别是当检索表格的很大一部分时。
这在一定程度上是因为索引查找本身的开销,而TABLE ACCESS FULL操作不会发生这种情况。这主要是因为索引查找一个块接一个地读取,因为在处理完当前块之前,数据库不知道下一个要读取哪个块。FULL TABLE SCAN无论如何都必须获取整个表,这样数据库才能一次读取更大的块(多块读取)。尽管数据库读取的数据更多,但它可能需要执行更少的读取操作。
数据库不使用索引,因为它不能任意使用联合索引中的单列。仔细观察一下索引结构就可以明白这一点。
与其他任何索引一样,联合索引只是一个B树索引,它将索引数据保持在排序列表中。数据库根据每个列在索引定义中的位置,对索引条目进行排序。第一列是主要排序标准,第二列仅在第一列中有两个条目具有相同值时才确定顺序,依此类推。
Important
联合索引指的是多个字段组合成的一个索引。
因此,双字段索引的排序就像电话本:先按姓排序,然后再按名字排序。这就是说,双字段的索引不支持单独使用第二个字段搜索;那会像通过名字搜索电话一样。
图 2.1 联合索引
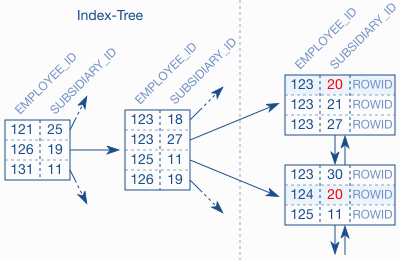
图2.1 节选的索引显示了子公司20的条目没有排列在一起。很明显树中也没有 susidiary_id=20的条目,虽然它们存在于叶节点中。因此树对于这个查询是无用的。
Tip
Visualizing an index helps in understanding what queries the index supports. You can query the database to retrieve the entries in index order (SQL:2008 syntax, see syntax of top-n queries for proprietary solutions using LIMIT, TOP or ROWNUM):
SELECT <INDEX COLUMN LIST> FROM <TABLE> ORDER BY <INDEX COLUMN LIST> FETCH FIRST 100 ROWS ONLYIf you put the index definition and table name into the query, you will get a sample from the index. Ask yourself if the requested rows are clustered in a central place. If not, the index tree cannot help find that place.
当然,我们也可以在subsidiary_id上添加另一个索引,提高查询速度。不过还有个更好的方案 —— 至少如果我们假设仅在EMPLOYEE_ID上搜索是没有意义的。
我们可以利用一下
我们可以利用这样一个事实,即第一个索引列始终可用于搜索。同样,它就像一个电话簿:你不需要知道名字就可以按姓氏搜索。诀窍是颠倒索引列的顺序,使SUBSIDIARY_ID位于第一个位置:
CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID)这两列加在一起仍然是唯一的,因此具有完整主键的查询仍然可以使用INDEX UNIQUE SCAN,但索引项的顺序完全不同。SUBSIDIARY_ID已成为主要的排序标准。这意味着一个子公司的所有条目都连续地存在索引中,因此数据库可以使用B树来找到它们的位置。
Important
The most important consideration when defining a concatenated index is how to choose the column order so it can be used as often as possible.
执行计划确认数据库用了”反转“的索引,subsidiary_id 不再是唯一的,因此要查找所有匹配的条目,数据库必须进入叶节点:因此而使用索引范围扫描操作。
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 106 | 75 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 106 | 75 |
|*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 106 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SUBSIDIARY_ID"=20)MySQL
+----+-----------+------+---------+---------+------+-------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+------+---------+---------+------+-------+
| 1 | employees | ref | PRIMARY | 5 | 123 | |
+----+-----------+------+---------+---------+------+-------+
The MySQL access type ref is the equivalent of INDEX RANGE SCAN in the Oracle database.一般来说,数据库在搜索最前面(最左边)的列时可以使用联合索引。三个字段的联合索引,可以用在搜索第一列、将前两列一起搜索以及使用所有列进行搜索的这些情况。
尽管双索引解决方案也提供了非常好的选择性能,但单索引解决方案更可取。它不仅节省了存储空间,而且还节省了第二个索引的维护开销。表的索引越少,插入、删除和更新性能就越好。
要定义最佳索引,您必须不仅了解索引是如何工作的,还必须了解应用程序是如何查询数据的。这意味着您必须知道where子句中出现的列组合。
因此,对于外部顾问来说,定义最佳索引非常困难,因为他们没有应用程序访问路径的概述。顾问通常只能考虑一个查询。它们没有利用索引可能为其他查询带来的额外好处。数据库管理员的处境类似,因为他们可能知道数据库模式,但对访问路径没有深入的了解。
技术数据库知识与业务领域的功能知识相符合的唯一地方是开发部门。开发人员对数据有感觉,并且知道访问路径。它们可以适当地进行索引,从而在不付出太多努力的情况下为整个应用程序获得最佳效益。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博