Docker 构建缓存终极指南

本指南将帮助你了解 Docker 构建缓存的工作原理。我们将首先回顾一些关于工作流和镜像层的 Docker 基础知识(可选),随后深入探究构建缓存的细节,并学习提升缓存效率的相关概念与最佳实践。毕竟,谁不想让构建过程变得更快呢?
Docker 基础知识
借此机会学习新知识,或温习一下关于 Docker 工作流及镜像层运作机制的记忆。
Docker 工作流
Docker 是一个平台,让你能够以可靠的方式,在任何需要的地方运行你的应用。你可以将应用程序打包成一个“镜像”(Image),随后在本地机器、生产环境,乃至介于两者之间的任何环境中,将其运行于相互隔离的“容器”(Container)之中。这一过程通常被称为“应用程序容器化”。
从源代码到最终运行的应用程序,其宏观工作流大致如下:
- 你首先需要准备好“构建上下文”(Build Context)以及一个 Dockerfile 文件。
- 构建器(Builder)将依据 Dockerfile 中的指令,来构建生成一个镜像。
- 随后,你可以在一个或多个容器中,运行该镜像的实例。
下图展示了这一工作流:
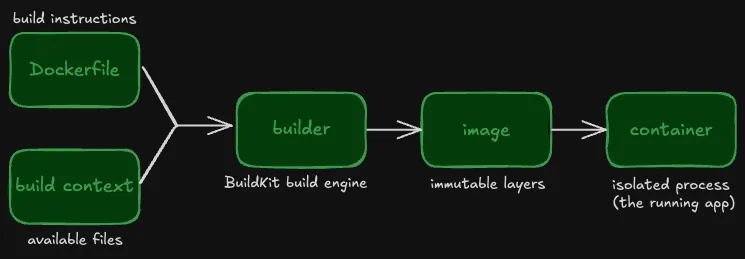
从源码中构建工作流,运行中容器的 Docker
关键术语
Dockerfile:用于构建镜像的指令集。
构建上下文(Build context):构建器在镜像构建过程中能够访问的主机文件。主要包含你的应用程序源代码。
构建器(Builder):根据 Dockerfile 创建镜像的构建引擎(BuildKit)。如需了解 BuildKit 的工作原理,请参阅《BuildKit 深度解析:Docker 构建引擎详解》。
镜像(Image):基于 Dockerfile 和构建上下文构建而成的不可变软件包。镜像包含了运行应用程序所需的一切:源代码、语言运行时环境、依赖项、配置文件以及环境变量。你可以使用单个镜像来运行多个容器。
容器(Container):镜像的一个运行实例,为应用程序提供了一个隔离的运行环境。
构建器如何根据 Dockerfile 创建镜像层
什么是 Docker 镜像层?它们又是如何被创建的?正是 Dockerfile 精确地决定了镜像的分层方式及构建过程。
Dockerfile 是一个文本文件,其中包含一系列用于构建镜像的有序指令。以下示例展示了一个 Node.js 应用所用 Dockerfile 的部分内容:
FROM node:20
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm install
COPY . ..为了构建镜像,构建器按照指令在 Dockerfile 中出现的顺序执行这些指令。
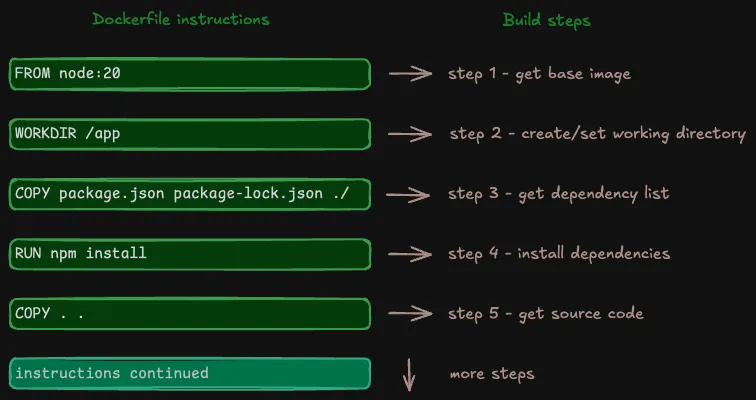
Dockerfile 指令如何映射到各个构建步骤
根据指令的不同,每个构建步骤会产生以下一项或两项结果:
- 一个文件系统层
- 元数据
这些独立的文件系统层和元数据将成为最终 Docker 镜像的一部分。
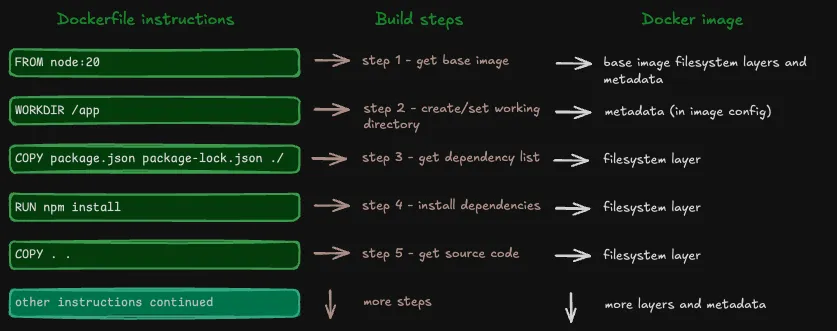
每一条指令都会在最终镜像中创建文件系统层和/或元数据。
但是,Docker 镜像不仅仅包含文件系统层和元数据。每一个镜像都包含一个镜像配置 JSON 文件,该文件用于记录构建缓存和镜像历史所需的层引用信息,同时也存储了元数据。
指令转化为镜像层和元数据
COPY、RUN 和 ADD 指令会生成文件系统层,Docker 会将这些层存储在镜像内部。
而像 ENV、EXPOSE 和 CMD 这样的其他指令,则会生成元数据;Docker 会将这些元数据存储在镜像配置 JSON 文件中。
注:WORKDIR 指令会在指定的目录不存在时自动创建该目录。构建器(Builder)会将这一变更作为元数据存储在镜像配置中,而不会为此单独创建一个文件系统层。
镜像层是如何(以及为何!)堆叠在一起的
在上一节中,你已经了解了 Dockerfile 指令在构建过程中是如何转化为 Docker 镜像中的文件系统层或元数据的。你也知道了这些指令是按顺序排列的,且构建器会严格按照顺序执行每一个步骤。那么,为什么指令的顺序如此重要呢?
镜像构建过程中的每一个步骤都依赖于前一步骤,并在其基础上进行增量修改。下图所示的镜像构建示意图,直观地展示了文件系统层是如何逐层堆叠起来的。
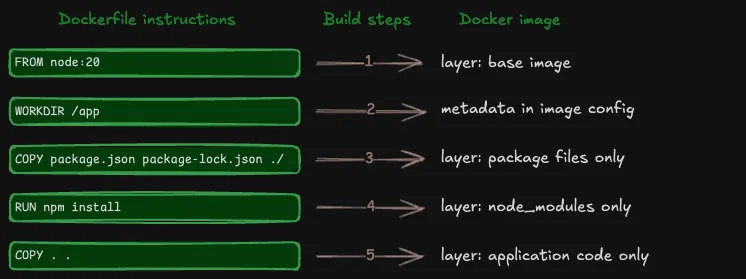
层层堆叠:每一层仅存储相对于上一层的变更
Docker 镜像中的每一层仅存储相对于上一层的变更内容。例如,如果某一层包含文件 A 和 B,而下一层新增了文件 C,那么新的一层将仅存储文件 C,而不会包含 A、B 和 C 的副本。后续的各层也会以同样的方式,在现有层的基础上继续构建。
最终,当你将镜像运行于容器中时,Docker 会获取这些文件系统层,按顺序将其堆叠并合并,从而为容器呈现出一个统一的、单一的文件系统。
(Docker 的另一个组件——containerd——负责读取配置信息,并将其应用到容器运行环境中。)
Docker 镜像中这些独立堆叠的层结构,非常适合在后续的构建任务中进行复用,也便于在不同的镜像之间共享(对于完全相同的构建指令,Docker 会自动执行这种共享操作)。本文接下来的部分将重点探讨如何利用 Docker 构建缓存(Build Cache)机制,在后续构建中实现层的复用。
若想深入探究镜像层的具体格式,请参阅文章:《从零开始构建容器:层》(Building containers from scratch: Layers)。
理解 Docker 构建缓存
构建缓存通过复用现有的镜像层及元数据,从而显著提升镜像构建的速度。当你对镜像进行重建时——特别是当变更内容极少甚至没有变更时——构建器(Builder)便会复用此前构建过程中已完成的工作成果。当开发者提及“层缓存”(Layer Caching)这一术语时,他们指的正是创建并随后复用镜像层的这一整套流程。
关于缓存机制
无论是计算机内存中的缓存,还是像 PostgreSQL 数据库中实现的缓存,其核心原理都是利用一种高速的临时存储介质,来存放那些被频繁访问的数据。这样一来,需要使用这些数据时便能实现快速提取。然而,Docker 的构建缓存机制在运作方式上略有不同。构建缓存的主要作用是追踪变更记录,从而使构建器能够复用此前已执行过的构建任务成果。而镜像本身,则负责实际存储这些分层数据。这种机制不仅减少了冗余的重复工作,更极大地加快了后续镜像构建的速度。
Docker 构建缓存的工作原理
当你对镜像进行重建时,构建器会像处理首次构建任务一样,逐条、按序地执行 Dockerfile 中的各项指令。但此时,构建器不再是简单地逐一执行每一条指令,而是会针对当前已有的镜像层及元数据,对这些指令进行逐一比对与校验。
Docker 构建缓存跨构建周期的运作流程如下所示:
- 镜像的首次构建:构建器会执行所有的具体任务(例如复制文件、运行各类命令等)。构建缓存负责记录构建过程中所执行的工作。
- 对于同一镜像的后续构建,构建器会利用构建缓存来检测自上次构建以来是否有任何变动:
- 无变动:直接复用此前的工作成果。
- 有变动:从发生变动的那一步起,重新执行后续的所有工作(即缓存失效)。
以下是一个图解示例,展示了构建缓存如何在不同次构建之间发挥作用:
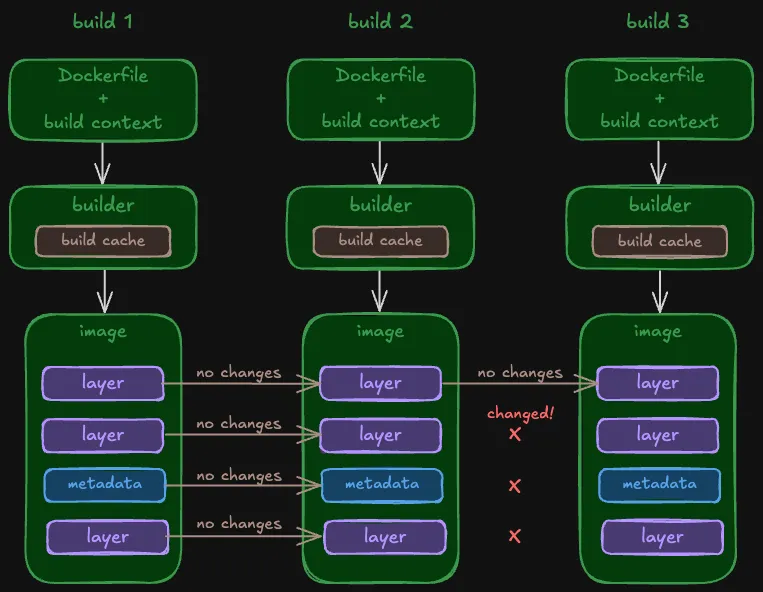
如何构建缓存,使之在有或没有变更的构建之间运作
如果某条指令与上一镜像相匹配,构建器将跳过该指令的执行,直接进入下一步。当所有指令均相匹配时,无需进行任何重建工作;构建器只需生成一个新的镜像配置,该配置将引用并复用上一镜像中的各个层(layers)。
如果某条指令与当前镜像不匹配,构建器便会执行该指令,从而创建一个新层,或利用新的元数据更新镜像配置。一旦遇到首条发生变更的指令,构建缓存即告失效。
深入解析缓存失效机制
所谓缓存失效,是指构建器无法复用既有的层,而必须重新执行相应的工作。其根本原因在于:镜像层具有“不可变性”(immutable),即一旦生成便无法被修改或更新。当构建器在 Dockerfile 中遇到某条与上一轮构建相比已发生变更的指令时,便会触发缓存失效。

缓存失效:当一条指令发生更改时,所有后续指令都必须重建缓存。
第一条发生更改的指令会使该指令及其在 Dockerfile 中后续所有指令的缓存失效。缓存失效的工作原理是,每一层仅包含与上一步相比发生更改的内容。每一层都依赖于前一层来创建一个连贯的最终文件系统,以便在容器中运行。
缓存失效并不意味着构建失败。构建会继续进行,但构建器必须为已更改的指令及其后续所有指令执行命令、创建层并重新存储元数据。
构建缓存的行为因 Dockerfile 指令而异。以下部分将解释一些可能一开始并不明显的行为。
仅配置指令的缓存失效
某些 Dockerfile 指令(包括 ENV、EXPOSE、WORKDIR 和 CMD)仅添加或更改镜像配置中的元数据,而不会创建文件系统层。
当指令字符串发生更改时,构建器会使这些指令的缓存失效。例如,将 ENV NODE_ENV=development 更改为 ENV NODE_ENV=production 会使缓存失效。如果指令字符串未更改,构建器会重用上次构建的元数据。
ADD 和 COPY 指令的缓存失效
ADD 和 COPY 指令会将文件移动到镜像中。构建器会计算所有文件的缓存校验和,以确定是否可以重用该层。如果任何文件发生更改,构建器会在该步骤使缓存失效。
文件修改时间 (mtime) 的更改不会影响缓存。构建器不会将仅更改 mtime 视为导致缓存失效的更改。
RUN 指令的缓存失效
RUN 指令的构建缓存行为起初可能令人意外。构建器仅检查 RUN 指令字符串的更改。构建器不会检查指令获取的外部引用的更改。
例如:
- 1 月 1 日:你首次构建镜像。
RUN apt-get update指令会获取当前软件包列表,构建缓存会缓存该层。 - 1月9日:发布了新的安全软件包。
- 1月10日:你重新构建镜像。构建缓存显示
RUN apt-get update指令未更改。构建器重用了1月1日的软件包列表缓存层,而不是获取新的安全软件包。
外部引用可以包括操作系统软件包管理器(如 apt 或 apk)获取的资源、直接下载的资源以及 git 克隆的资源。
要强制构建器获取最新的外部资源,你需要在执行该 RUN 指令之前或之时使缓存失效。常见的“清除缓存”方法包括:
- 使用在构建过程中会发生变化的构建参数。在
RUN指令之前添加一个ARG来定义参数,并在构建时更新该参数:docker build --build-arg INVCACHE="新字符串"。 - 在
RUN指令字符串的末尾添加包含日期或版本号的注释。 - 将
apt-get update和apt-get install合并到一条指令中,以确保在更改已安装的软件包时始终运行apt-get update。你还可以在指令中包含软件包版本,以便在版本更改时使缓存失效。例如:RUN apt-get update && apt-get install -y package=1.2
要完全重新开始,请使用 --no-cache 选项构建镜像以跳过所有缓存层。更多详细信息,请参阅“构建无缓存的 Docker 镜像”。
注意:带有绑定挂载的 RUN 指令是此规则的例外。对于带有绑定挂载的 RUN` 指令,构建器会根据挂载的文件计算缓存校验和,以确定缓存是否有效,就像它对 ADD 和 COPY 指令所做的那样。我们将在后面的“绑定挂载和缓存失效”部分详细介绍这一点。
构建器将构建的缓存存储在哪里
默认情况下,构建器会将构建缓存和镜像存储在你的本地计算机上。
你无需直接访问缓存目录,因为构建器会为你处理缓存的存储和检索。虽然你可以通过 Docker 命令(例如 docker inspect 和 docker save)访问和检索数据。
删除镜像时,缓存仍会保留其他镜像正在使用的层。要清除旧的缓存数据,请参阅“手动清除构建缓存”。
对于 CI/CD 流水线或跨多台机器的构建,构建器支持将缓存导出到远程存储。有关远程缓存选项的详细信息,请参阅 Docker 文档中的“缓存存储后端”。
优化 Docker 镜像构建以提高重用性
优化 Docker 镜像构建以有效利用构建缓存,可以加快首次构建和后续构建的速度。以下部分概述了影响构建缓存的优化方法。
有关更多优化 Docker 构建的方法,请参阅“如何加快 Docker 构建速度”和“如何减小 Docker 镜像大小”。
在 Dockerfile 中使用逻辑顺序
既然你已经了解了构建缓存(Build Cache)的工作原理,想必你也明白了为什么 Dockerfile 中指令的顺序至关重要。在编写 Dockerfile 时,应始终按照“变动频率由低到高”的顺序来排列指令,以确保构建器能够在缓存失效之前,尽可能多地重用已有的镜像层。
为了加快构建速度——特别是针对 JavaScript 和 Python 这类语言——一个行之有效的最佳实践是:先安装依赖项,然后再复制源代码。
Node.js:
COPY package*.json . # copy package.json
RUN npm install # install dependencies
COPY . . # copy source codePython:
COPY requirements.txt . # copy requirements.txt
RUN pip install -r requirements.txt # install dependencies
COPY . . # copy source code为什么将依赖项的安装步骤前移至 Dockerfile 的较早位置,会对构建速度产生如此巨大的影响?这种优化之所以奏效,原因在于:
- 依赖项的变动频率远低于源代码;
- 安装依赖项的过程通常耗时较长。
最小化构建上下文与镜像层
为了确保构建过程的高速运行并保持镜像层体积小巧,你应该仅允许构建器访问其所需的特定文件,并仅将必要的源代码文件通过 COPY 指令复制到 Docker 镜像层中。
首先,你应该始终从尽可能小的构建上下文入手,以此限制在两次构建之间可能发生变动的文件数量,从而避免因文件变动而导致构建缓存失效。
构建上下文(Build Context)包含了构建过程所能访问的所有文件。你可以在 docker build 或 depot build 命令中指定构建上下文,通常指定为一个目录路径,或者指向代码仓库或特定文件的远程 URL。
在许多示例中,你会看到构建命令将当前目录(用符号 . 表示)指定为构建上下文;这意味着当前目录下的所有文件都将对构建器开放并可供使用:
docker build -t example-app:latest .如果你将当前目录用作构建上下文,请确保其中不包含任何不必要的文件。
使用 .dockerignore 排除不必要的文件
你或许能想到,在工作目录或代码仓库中,有些文件在构建阶段(即构建器创建镜像时)或运行阶段(即你的应用程序在容器中运行时)是完全用不到的。
你应当使用 .dockerignore 文件来将这些文件从构建上下文中排除。请排除构建器不需要的文件,同时也排除那些在构建过程中无论如何都会自动生成的文件(即构建产物)。
对于 Node.js 应用,.dockerignore 文件的内容可能如下所示:
node_modules # Dependencies rebuilt during build (can be huge)
.git # Version control (not needed for image, also potentially huge)
.gitignore # Git config (not needed for image)
README.md # Documentation (not needed for image)
dist/* # Build artifacts rebuilt during build除了创建更小的层(layers)之外,利用 .dockerignore 文件排除特定文件也有助于避免缓存失效,因为它能防止将不需要的、已更改的文件复制到镜像层中。
利用多阶段构建(Multi-stage builds)来降低缓存失效的影响
多阶段构建具有诸多优势:
- Dockerfile 结构更加清晰,易于维护。
- 由于支持并行构建,构建速度更快。
生成的镜像体积更小。
构建缓存的利用效率更高。
我们在此不深入探讨多阶段构建与本文开头介绍的“线性构建”在细节上的具体差异。不过,这里简要概述了如何组织多阶段构建,以实现更高效的构建缓存利用:
将构建过程划分为多个阶段,每个阶段各司其职。一种常见的做法是:设置一个专门用于构建应用程序(构建时环境)的阶段,以及另一个专门用于构建最终镜像(运行时环境)的阶段。
- 每个阶段都必须以一条
FROM指令作为起始。 - 某一构建阶段中的变动,不会自动导致其后续阶段的缓存失效。
在使用分阶段构建来隔离“构建时”与“运行时”依赖项时,关于缓存机制最关键的一点在于:你可以更新构建时的环境配置,而无需担心这会导致其他镜像层(layers)的缓存失效。
如需深入了解 Docker 多阶段构建的细节,或参考最佳实践范例,请查阅我们提供的“最佳 Dockerfile 示例”。
在不使用缓存的情况下构建 Docker 镜像
至此,你已经充分了解了构建缓存对于优化构建流程所带来的诸多益处。那么,为何有时我们反而会选择在不使用缓存的情况下进行构建呢?
也许你正在调试某个问题,需要彻底从零开始进行构建;又或者你需要强制 Docker 更新某个外部资源的缓存;再或者,你正遵循 Docker 的最佳实践建议,定期重建镜像以确保其始终保持最新状态并具备良好的安全性。
若要在构建镜像时跳过构建缓存,只需在构建命令中添加 --no-cache 选项即可:
docker build --no-cache .对于多阶段构建,若要在构建过程中忽略一个或多个阶段的构建缓存,请使用 no-cache-filter 选项:
docker buildx build --no-cache-filter stage2 .用于缓存优化的高级功能
除了标准的构建缓存之外,该构建器(builder)还包含了一些额外的缓存功能,旨在生成更小的镜像并加快构建速度:即绑定挂载(bind mounts)和缓存挂载(cache mounts)。
绑定挂载和缓存挂载为构建器提供了不同的方式,使其能够在构建过程中(通过 `RUN` 指令)访问文件,而无需将这些文件包含在镜像层中。
用于临时文件访问的绑定挂载
当你的构建过程需要临时访问源代码以生成最终镜像所需的构建产物(artifact)时,请使用绑定挂载来优化缓存。
将绑定挂载与 RUN 指令配合使用,可以让构建上下文中的文件仅对该特定的 RUN 指令临时可用,而不会将这些文件添加到镜像层中。绑定挂载的目标路径必须存在于您的构建上下文中。它们是只读且临时的;当 RUN 指令执行完毕后,构建器会自动卸载这些绑定挂载目标。
注意:你也可以在通过 docker run 运行容器时使用绑定挂载,以便在宿主机与容器之间共享文件(不过,运行容器并非本文的重点)。
对于涉及编译型语言的构建项目,绑定挂载在优化构建缓存方面尤为有用。
以 Go 或 Rust 项目为例,你的最终镜像中只需要包含编译好的二进制文件,而无需包含所有的源代码。此时,你可以使用绑定挂载来临时赋予构建器访问源代码的权限,以便进行二进制编译,同时避免将所有的源文件都打包进镜像层中。以下是一个 Go 项目的示例:
# Instead of:
COPY . . # adds source code to an image layer
RUN go build -o /app # compiles binary from source code
# Use a bind mount to temporarily include the source code for the go build command:
RUN --mount=type=bind,target=. go build -o /app在你的 Dockerfile 中,与其先执行 COPY 指令再执行 RUN 指令,不如将包含源代码的目标目录通过“绑定挂载”(bind mount)的方式挂载到 RUN 指令中。这样一来,你就成功避免了为镜像额外增加一个庞大且不必要的层(layer)。
绑定挂载有助于加快构建速度,减少因源代码变更导致的缓存失效问题,并最终生成体积更小的镜像。
绑定挂载与缓存失效
与常规的 RUN 指令不同,当你使用绑定挂载时,构建器(builder)会根据被挂载文件的元数据来计算缓存校验和。一旦有任何文件发生变动,构建器就会判定该 RUN 步骤对应的缓存已失效。
对于使用了绑定挂载的 RUN 指令而言,其缓存失效机制与 ADD 和 COPY 指令完全一致。
用于持久化存储的缓存挂载
你可以利用“缓存挂载”(cache mounts)为各类工具(例如包管理器)创建持久化的缓存存储空间,从而允许这些工具利用自身的逻辑来管理和验证缓存。
通过缓存挂载,你可以指定一个独立于镜像层之外的持久化缓存位置;构建器可以在多次构建过程中反复对该位置进行读写操作。
常规的构建缓存会在指令或相关文件发生变更时自动失效;与此不同,缓存挂载能够保持持久化状态,并允许包管理器运用其自身的验证逻辑来判断哪些软件包可以被复用。
包管理器缓存示例:npm
在 Depot 平台中,其推荐的最佳 Dockerfile 实践正是利用缓存挂载技术,将包管理器的缓存存储在 Docker 构建缓存体系之外。这样一来,当项目依赖项发生变更时,包管理器只需下载那些新增或已更新的软件包即可。
与绑定挂载的操作方式类似,你需要将缓存挂载配置与相应的 RUN 指令进行搭配使用。以下是一个示例,展示了如何在一个使用 npm 包管理器的 Node.js 应用程序的 Dockerfile 中应用这一技术:
RUN --mount=type=cache,target=/root/.npm \
npm ci --no-audit --no-fund--mount=type=cache,target=/root/.npm 选项指示构建器在 npm 的缓存目录处挂载一个缓存,该缓存可在多次构建之间持久保存。当依赖项发生变化时,npm 会从该缓存中复用未更改的软件包,而无需重新下载所有内容。
包管理器缓存示例:Go modules
缓存挂载对于多阶段构建非常有用,因为挂载的缓存使得相同的依赖项能够在构建、测试及其他阶段之间共享使用。下面的 Dockerfile 片段展示了一个针对 Go 应用的缓存挂载示例:
FROM base AS test
RUN --mount=target=. \
--mount=type=cache,target=/go/pkg/mod \
go test .选项 --mount=type=cache,target=/go/pkg/mod 告知构建器挂载一个用于 Go 模块的缓存,该缓存可在多次构建之间持久保存。每一个需要依赖项的构建阶段都可以访问该 Go 模块缓存,并重用那些未发生更改的软件包。
注意:缓存挂载在同一个构建器实例的多次构建之间是持久存在的;但除非经过专门配置,否则它们不会在不同的构建机器或 CI/CD 运行之间自动共享。
缓存挂载能够提升构建性能,因为构建器无需重复下载依赖项。如需了解更多信息,请参阅关于如何利用缓存挂载加速构建过程,以及如何在持续集成(CI)环境中应用缓存挂载的相关文档。
释放 Docker 占用的更多磁盘空间
当您频繁使用 Docker 时,未使用的镜像、容器和数据卷会逐渐堆积,因此需要进行清理。
检查当前磁盘使用情况
首要步骤是运行 docker system df 命令,以获取各类对象所占用的磁盘空间概览,并查看有多少空间可以被回收。该概览摘要的显示效果如下:
$ docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 138 34 36.18GB 34.15GB (94%)
Containers 74 18 834.8kB 834.6kB (99%)
Local Volumes 118 6 15.31GB 15.14GB (98%)
Build Cache 245 0 1.13GB 1.13GB一旦确定了哪些资源可以回收,你就可以针对各类对象使用 Docker 的 prune(修剪)命令,从而释放大量的磁盘空间。
若要了解如何使用各类 Docker prune 命令来清理非缓存对象,请参阅《如何清除 Docker 缓存并释放系统空间》。
构建缓存的垃圾回收
构建器(Builder)会在后台定期运行垃圾回收程序,以自动修剪缓存。默认的垃圾回收策略规定了构建器何时以及如何清理未使用的缓存,或清理超出构建缓存大小限制的缓存。Docker 在其《构建垃圾回收》文档中列出了这些默认的垃圾回收策略。
如果你正在管理大规模的构建任务,或者使用的是自托管的构建器,建议你考虑自定义垃圾回收策略;因为在这种情况下,你可能需要更频繁地进行垃圾回收,或者需要设定更大的构建缓存大小限制。
手动清除构建缓存
Docker 为各类对象都提供了相应的 prune 命令,构建缓存也不例外。通过 docker buildx prune 命令的各项选项,你可以自定义清理操作。以下汇总了一些常用的命令:
仅移除那些未被任何构建任务引用的中间层(也称为“悬空”层):
docker buildx prune清除所有未使用的构建缓存:
docker buildx prune --all指定一个非当前构建器的构建器,并从缓存中移除悬空层:
docker buildx --builder builder-name prune若要指定一个时间跨度,以便在此时间之后清除缓存,请结合使用 --filter 选项和 until 标志。此命令将清除早于 2 天的缓存:
docker buildx prune --filter until=48h若要释放空间,但同时为你的最新工作保留特定容量,请使用 --keep-storage 选项。该命令将保留最近使用的 10GB 缓存,并删除其余部分:
docker buildx prune --keep-storage 10GB如需了解有助于自定义缓存清理操作的选项和标志的详细信息,请参阅 Docker Buildx Prune 参考文档。
Depot 如何优化 Docker 缓存
即使采用了经过优化的 Dockerfile 和高级缓存机制,默认的构建缓存也仅在执行镜像构建的那台机器上才有效。当你在不同的环境中进行构建时——无论是通过 CI/CD 流水线,还是在队友的机器上——构建过程都不得不从头开始。
Depot 的容器构建服务会将你的构建缓存存储在靠近构建执行位置的高速存储介质上,从而免去了在不同构建任务之间通过网络传输缓存的繁琐步骤。这些缓存会自动持久化保存,并可在整个团队成员及 CI 构建任务之间实现共享。
无论你在何处运行 docker build 命令,都可以轻松切换至 depot build,从而在不同的机器和环境之间实现构建缓存的共享。
 上一篇
上一篇 
 QQ 空间
QQ 空间
 QQ 好友
QQ 好友
 微博
微博